Herein lies selected work from recent data science projects.
Udacity Data Analyst Nanodegree Project Portfolio
The Udacity Data Analyst Nanodegree requires a pre-requisite familiarity and experience in statistics and computer programming, followed by completion of several courses that continue to develop data science and analysis skills. Each course consists of online learning content designed to enable the completion of a project. Each project and the associated code is reviewed for compliance with a rubric. Learn more about the program here.
Make An Effective Data Visualization
Skills Developed: HTML, CSS, SVG, DIMPLE.JS, D3.JS, DESIGN PRINCIPLES, VISUAL ENCODINGS
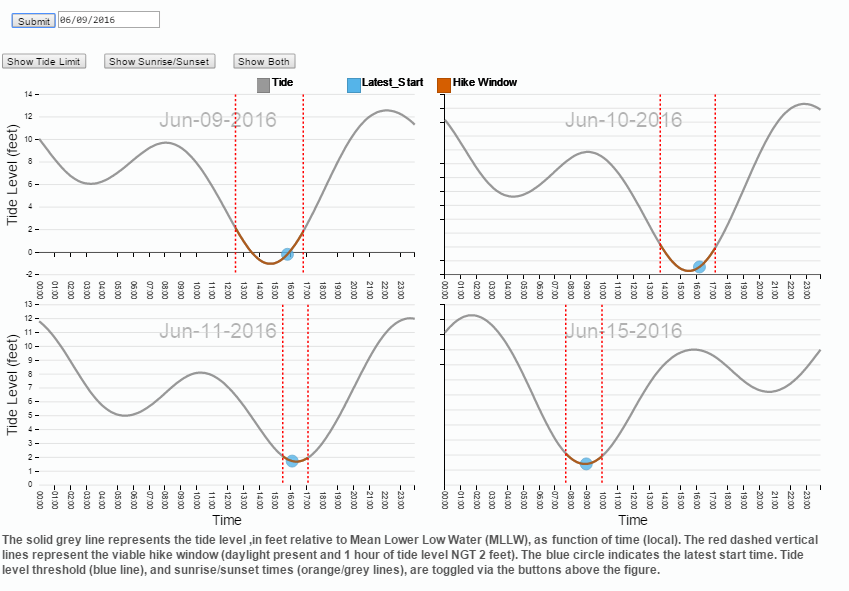
This course focuses on the principles and tools (dimple.js, d3.js) for creating an effective data visualization. For my project I wrangled and transformed tide data in python, then used dimple, d3, moment, and vanilla javascript to create an interactive visualization designed to help the user determine when to attempt a low tide hike between two parks in North Seattle. The visualization allows the user to input a date, and the next four viable hiking windows are displayed. The user can also view the threshold tide level and sunrise sunset times for context as to how the window is calculated. View a live version of my final project visualization here: Seattalytics. Source code and additional project details are available at the project Github Repository.
Identifying Fraud from Enron Email
Skills Developed: PYTHON, SCIKIT-LEARN, NATURAL LANGUAGE PROCESSING, FEATURE SELECTION, VERIFYING MACHINE LEARNING PERFORMANCE This course and project focused on developing a machine learning algorithm for identifying fraud, using the Enron data set. While this was not my first exposure to machine learning, it was the first exposure to sklearn. I enjoyed building pipelines for feature selection and tuning as well as balancing recall and precision on a sparse data set. Source code and additional project details are available at the project Github Repository.
Explore and Summarize Data
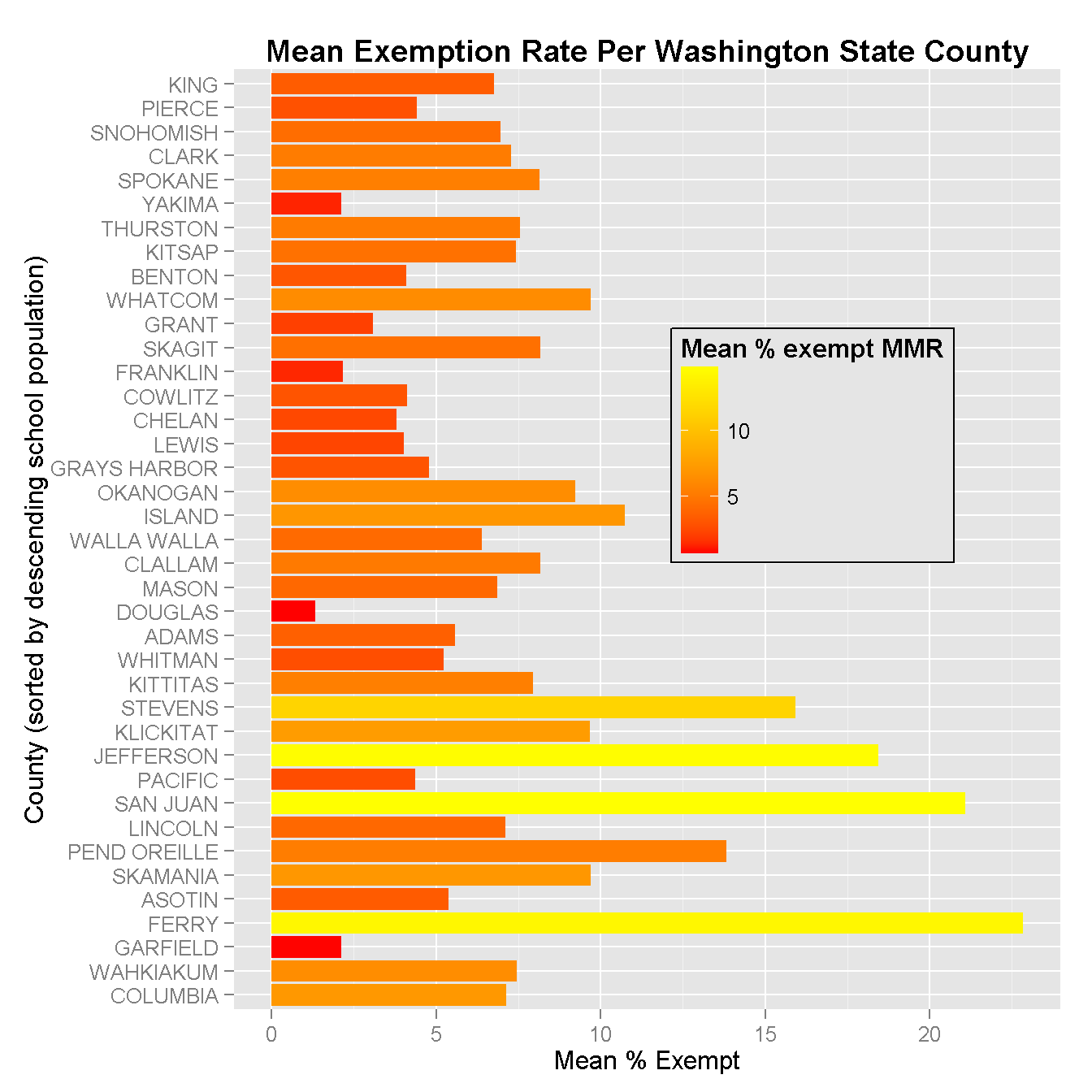
Skills Devloped: RSTUDIO, R PACKAGES, PLOTTING IN R, EXPLORATORY DATA ANALYSIS TECHNIQUES This course focuese on buidling exploratory data anlaysis (EDA) skills and executing EDA in R. During the course of my project I used R to perform EDA on a Washington State school vaccine exemption data set (school years 2011, 2012, 2013) provided by the WA Department of Health (DOH). The data required extensive cleaning and wrangling, prior to exploration. This was my first experience cleaning data in R, haveing previously used python for these tasks.n It was an enjoyable challenge. My favorite part of this experience was learning about “tidy” data and using specific R packages to tidy the data (dplyr, tidyR etc), and chaining code. Another useful aspect was learning to use RStudio to create .MD files and knit them into html for publication. Source code and additional project details are available at the project Github Repository.
Analyzing the New York Subway Dataset
Skills Developed: PYTHON, NUMPY, PANDAS, GGPLOT, LINEAR REGRESSION, SQL QUERIES, PANDASQL, IPYTHON NOTEBOOK This course focuses on analyzing and reporting on a NYC subway data set from May 2011, specifically to determine factors that affect ridership. This was a great introduction to data science topics and tools including data wrangling, I/O methods, plotting in python, machine learning, statistical analysis, SQL, PANDAs, IPython Notebook (Jupyter Notebook) and map-reduce. I really enjoyed integrating a variety of computational tools to collate and interrogate the data. Source code and additional project details are available at the project Github Repository.
Data Wrangle OpenstreetMaps Data
Skills Developed: PYTHON, MONGODB, DATA VERIFICATION, DATA CLEANING This course focuses on how to acquire, audit, wrangle, and clean data, as well as how to reshape the data for MongoDB. Ultimately I used these skills to clean and explore OpenstreetMaps data for the Seattle area. The entire concept of programmatic data wrangling was new to me, as was the use of a nosql database (previous experience was with relational databases). It was intimidating at first but now I have to ability to take command of the data sets I’m interested in exploring. It has been a useful skill for subsequent projects and for the computational aspects of my proteomics and mass spectrometry work. Source code and additional project details are available at the project Github Repository.
Certificate of Completion

Past projects in which I have had involvement include:
- SPIRE: Systematic protein investigative research environment
- Design and Initial Characterization of the SC-200 Proteomics Standard Mixture
- IPM: An integrated protein model for false discovery rate estimation and identification in high-throughput proteomics
- Estimating false discovery rates for peptide and protein identification using randomized databases